 Widok zawartości stron
Widok zawartości stron
Nawigacja okruszkowa
Nawigacja
Widok zawartości stron
Widok zawartości stron
Kodowanie z UJ zmienia świat

Żyjemy w erze informacji – błyskawicznie podróżującej po całym świecie, przetwarzanej przez nasze komputery i smartfony. Jest ona zwykle poddana kompresji, co wielokrotnie obniża koszt jej przechowywania i przesyłania.
![]() Więcej o nauce?! Dołącz do profilu strony. www NAUKA.uj.edu.pl na Facebooku
Więcej o nauce?! Dołącz do profilu strony. www NAUKA.uj.edu.pl na Facebooku
Niektóre zadania, jak transmisja wideo, byłyby praktycznie niemożliwe bez kompresji, w tym przypadku, zmniejszającej wielkość pliku nawet do tysiąca razy. Dlatego niezwykle ważny jest rozwój technik kompresji danych, umożliwiający dalsze zmniejszanie plików, oraz obniżenie kosztu obliczeniowego kompresji: poprawę szybkości i zużycia energii – zarówno przez olbrzymie centra bazodanowe, jak i nasze smartfony. Te kluczowe parametry zostały ostatnio znacznie poprawione dzięki kodowaniu z UJ, które od 2014 roku wypiera stare metody w kompresorach m.in. Apple’a, Facebooka i Google’a.
Ciekawe? Przeczytaj także: Smoluchowski i Internet rzeczy
Co to jest kompresja danych?
Kompresja danych polega na wyodrębnieniu właściwej informacji z pliku, oraz optymalnym jej zapisaniu. Wykorzystuje ona fakt, że rzadkie zdarzenia niosą więcej informacji niż te częste. Przykładowo zdarzenie o prawdopodobieństwie 1/2 niesie 1 bit informacji, natomiast zdarzenie o prawdopodobieństwie 1/8 niesie 3 bity informacji. Przetworzenie ciągu takich zdarzeń (symboli), o zmiennej zawartości informacyjnej, w jak najkrótszy ciąg bitów (zer i jedynek) jest sercem kompresorów danych, formalnie zwanym kodowaniem entropijnym, ze względu na to, że jego stopień kompresji jest ograniczony przez tzw. entropię Shannona.
Podstawową metodą przetwarzania informacji jest kodowanie Huffmana, wprowadzone w 1952 roku. Zapisuje symbol bezpośrednio jako ciąg bitów, np. „A” jako „010”. Dzięki prostocie stało się ono sercem większości używanych przez nas kompresorów:
- gdy robimy zdjęcie lub oglądamy grafiki (kompresja obrazu), m.in. jpg, png,
- słuchamy muzyki, rozmawiamy przez telefon (kompresja dźwięku), m.in. mp3,
- używamy kompresji ogólnego użytku, m.in. zip, rar,
- i wielu innych sytuacjach, np. używając dokumentu typu pdf lub doc.
 Kodowanie Huffmana jest bardzo tanie obliczeniowo, jednak nie jest optymalne z powodu przybliżeń – pozostawia miejsce na poprawę stopnia kompresji. Przykładowo, symbol o prawdopodobieństwie 0.99 niesie tylko około 0.014 bita informacji, podczas gdy kodowanie Huffmana musi użyć dla niego przynajmniej 1 bit. Ta nieoptymalność (niedokładność) została naprawiona w zapoczątkowanym około 1960 roku kodowaniu arytmetycznym, które jednak zaczęło być powszechnie używane dopiero po 2000 roku, m.in. z powodu wyższych kosztów obliczeniowych. Osiąga ono praktycznie optimum (entropię Shannona). Obecnie wykorzystujemy je w kompresji wideo bez której pojedyncze filmy zajmowałyby setki gigabajtów.
Kodowanie Huffmana jest bardzo tanie obliczeniowo, jednak nie jest optymalne z powodu przybliżeń – pozostawia miejsce na poprawę stopnia kompresji. Przykładowo, symbol o prawdopodobieństwie 0.99 niesie tylko około 0.014 bita informacji, podczas gdy kodowanie Huffmana musi użyć dla niego przynajmniej 1 bit. Ta nieoptymalność (niedokładność) została naprawiona w zapoczątkowanym około 1960 roku kodowaniu arytmetycznym, które jednak zaczęło być powszechnie używane dopiero po 2000 roku, m.in. z powodu wyższych kosztów obliczeniowych. Osiąga ono praktycznie optimum (entropię Shannona). Obecnie wykorzystujemy je w kompresji wideo bez której pojedyncze filmy zajmowałyby setki gigabajtów.
tANS i rANS zastępują kodowanie Huffmana i arytmetyczne
Powyższy kompromis pomiędzy kodowaniem Huffmana (tanie, ale nieoptymalne) a kodowaniem arytmetycznym (optymalne, ale drogie), zakończył się dzięki obecnie używanej rodzinie kodowań Asymmetric Numeral Systems (ANS). Zostały one zapoczątkowane przez pracownika Instytutu Informatyki UJ, dr. Jarosława Dudę. W latach 2006–2014 wprowadził on kilka wariantów ANS. "Pierwszy wariant tego kodowania powstał w mojej pracy magisterskiej z fizyki w 2006 roku. Po jej publikacji pojawiło się zainteresowanie ze strony środowiska osób zajmujących się kompresją danych. Pod koniec 2007 roku wprowadziłem używany dzisiaj głównie wariant (tzw. tANS -tabled ANS). Potem temat ucichł na kilka lat, aż do końca 2013 roku, kiedy to pojawiły się pierwsze implementacje (zapisanie metody w postaci programu), pokazujące istotną wyższość ANS nad standardowymi metodami. Wówczas wszystko zaczęło się bardzo szybko rozwijać. Wprowadziłem bardzo odległy wariant (tzw. rANS - range ANS), który obecnie zyskuje na popularności. Zaczęły pojawiać się kompresory oparte na ANS – tworzone też przez gigantów jak Apple, Facebook czy Google.” – tłumaczy naukowiec.
Zwykle cała informacja w kompresorze ostatecznie jest przetwarzana przez kodowanie entropijne. Było ono kosztownym, wąskim gardłem, często decydującym o szybkości kompresji. ANS pozwoliło wielokrotnie zmniejszyć ten koszt oraz zmotywowało do szukania dalszych optymalizacji. Dzięki temu kodowanie Huffmana przyśpieszyło rzędu trzykrotnie w ciągu ostatnich 3 lat (dekodowanie z ok. 300MB/s/rdzeń i7 do ok. 1000MB/s). Ten istotny skok jednak brzmi skromnie w porównaniu z rzędu trzydziestokrotnym przyspieszeniem (z ok. 50MB/s do ok. 1500MB/s) dla dających lepszą kompresję dokładnych kodowań (porównanie).
W ostatniej dekadzie częstotliwości procesorów z powodu bariery technologicznej praktycznie się zatrzymały. Przykład ANS sugeruje że podstawowe używane metody mogą jeszcze pozostawiać dużo miejsca na poprawę – jest nauczką, że zawsze warto szukać dalej.
Ciekawe? Przeczytaj także: Nieśmiertelność już za 30 lat?
Co nam daje nowe kodowanie?
Z perspektywy użytkowników urządzeń elektronicznych, kodowanie ANS pozwoliło znacznie przyśpieszyć i zmniejszyć wielkości plików dla kompresorów powstałych od 2014 roku, już powszechnie przez nas używanych. Od połowy 2015 roku domyślnie zapisuje nim informację sprzęt Apple (iPhone, Mac), używając kompresora Apple LZFSE. W sierpniu 2016 roku Facebook przedstawił swój oparty na tANS otwarty darmowy kompresor Zstandard (zstd, wersja 7-Zip), który obecnie zaczyna zastępować powszechnie używany zlib (pliki typu zip), np. w dzienniku the Guardian, ze względu na wielokrotnie lepsze parametry (wykresy poniżej, kropki odpowiadają wybranej opcji kompresji od 1 do 22 dla zstd):
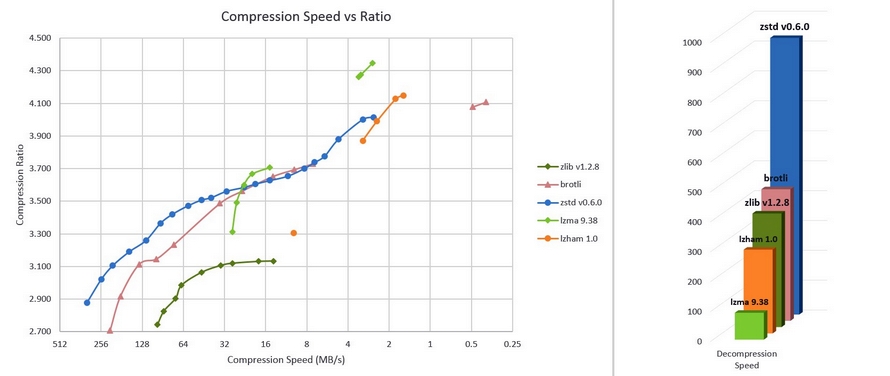
- zstd jest ponad dwukrotnie szybszy w dekompresji niż standardowy zlib, niezależnie od wybranej opcji (wykres słupkowy),
- podczas kompresji (wykres punktowy) jest ~3–5x szybszy dla podobnego stopnia kompresji (ilokrotnie zmniejszył plik), lub pozwala na znacznie lepszą kompresję.
Inny wariant tego kodowania (rANS) znacznie poprawił wydajność m.in. w kompresorze DNA: CRAM 3.0 z European Bioinformatics Institute oraz kompresji tekstur na GPU (m.in. do gier, rzeczywistości wirtualnej). Jest też używany w wersji rozwojowej darmowego kompresora wideo AV1 opracowywanego przez tzw. Alliance for Open Media (m.in. Google, Intel, Microsoft, Amazon, Netflix, Cisco, AMD, ARM, NVidia), który ma być używany m.in. do filmów w serwisach YouTube i Netflix.
---------------------------------------------
Do poczytania: Wikipedia, Infoq, Code.Facebook, Encode, The Guardian
Polecamy również


![Pszczoły na diecie? [wideo]](/documents/74541952/147053668/bee2_230x300.png/132b8ed5-2598-4f5d-a105-c565636e3911?t=1616428310238)